Micron Publishes Updated DRAM Roadmap: 32 Gb DDR5 DRAMs, GDDR7, HBMNext
by Anton Shilov on July 27, 2023 9:00 AM EST
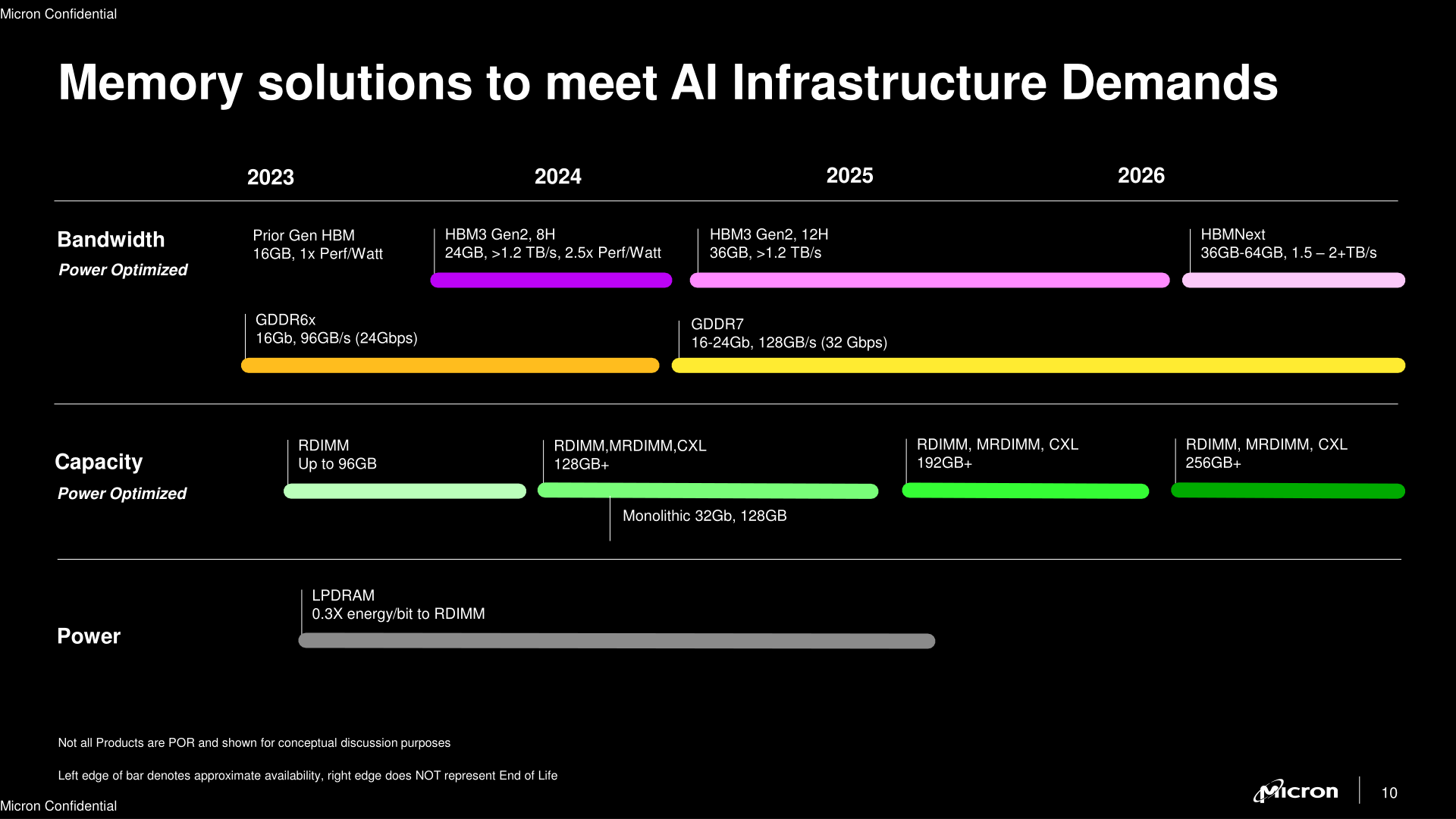
In addition to unveiling its first HBM3 memory products yesterday, Micron also published a fresh DRAM roadmap for its AI customers for the coming years. Being one of the world's largest memory manufacturers, Micron has a lot of interesting things planned, including high-capacity DDR5 memory devices and modules, GDDR7 chips for graphics cards and other bandwidth-hungry devices, as well as HBMNext for artificial intelligence and high-performance computing applications.
32 Gb DDR5 ICs
We all love inexpensive high-capacity memory modules, and it looks like Micron has us covered. Sometimes in the late first half of 2024, the company plans to roll-out its first 32 Gb DDR5 memory dies, which will be produced on the company's 1β (1-beta) manufacturing process. This is Micron's latest process node and which does not use extreme ultraviolet lithography, but rather relies on multipatterning.
32 Gb DRAM dies will enable Micron to build 32 GB DDR5 modules using just eight memory devices on one side of the module. Such modules can be made today with Micron's current 16 Gb dies, but this requires either placing 16 DRAM packages over both sides of a memory module – driving up production costs – or by placing two 16 Gb dies within a single DRAM package, which incurs its own costs due to the packaging required. 32 Gb ICs, by comparison, are easier to use, so 32 GB modules based on denser DRAM dies will eventually lead to lower costs compared to today's 32 GB memory sticks.
But desktop matters aside, Micron's initial focus with their higher density dies will be to build even higher capacity data center-class parts, including RDIMMs, MRDIMMs, and CXL modules. Current high performance AI models tend to be very large and memory constrained, so larger memory pools open the door both to even larger models, or in bringing down inference costs by being able to run additional instances on a single server.
For 2024, Micron is planning to release 128GB DDR5 modules based on these new dies. In addition, the company announced plans for 192+ GB and 256+ GB DDR5 modules for 2025, albeit without disclosing which chips these are set to use.
Meanwhile, Micron's capacity-focused roadmap doesn't have much to say about bandwidth. While it would be unusual for newer DRAM dies not to clock at least somewhat higher, memory manufacturers as a whole have not offered much guidance about future DDR5 memory speeds. Especially with MRDIMMs in the pipeline, the focus is more on gaining additional speed through parallelism, rather than running individual DRAM cells faster. Though with this roadmap in particular, it's clear that Micron is more focused on promoting DDR5 capacity than promoting DDR5 performance.
GDDR7 in 1H 2024
Micron was the first larger memory maker to announce plans to roll out its GDDR7 memory in the first half of 2024. And following up on that, the new roadmap has the the company prepping 16 Gb and 24 Gb GDDR7 chips for late Q2 2024.
As with Samsung, Micron's plans for their first generation GDDR7 modules do not have them reaching the spec's highest transfer rates right away (36 GT/sec), and instead Micron is aiming for a more modest and practical 32 GT/sec. Which is still good enough to enable upwards of 50% greater bandwidth for next-generation graphics processors from AMD, Intel, and NVIDIA. And perhaps especially NVIDIA, since this roadmap also implies that we won't be seeing a GDDR7X from Micron, meaning that for the first time since 2018, NVIDIA won't have access to a specialty GDDR DRAM from Micron.
HBMNext in 2026
In addition to GDDR7, which will be used by graphics cards, game consoles, and lower-end high-bandwidth applications like accelerators and networking equipment, Micron is also working on the forthcoming generations of its HBM memory for heavy-duty artificial intelligence (AI) and high-performance computing (HPC) applications.
Micron expects its HBMNext (HBM4?) to be available in 36 GB and 64 GB capacities, which points to a variety of configurations, such as 12-Hi 24 Gb stacks (36 GB) or 16-Hi 32 Gb stacks (64 GB), though these are pure speculations at this point. As for performance, Micron is touting 1.5 TB/s – 2+ TB/s of bandwidth per stack, which points to data transfer rates in excess of 11.5 GT/s/pin.








4 Comments
View All Comments
abufrejoval - Thursday, July 27, 2023 - link
Ever since you guys reported here on HBM being used in the consumer space on that famous small AMD GPU, I felt HBM was going to be mainstream. Going wide, stacked and close seems obvious when you need more bandwidth and lesser latencies.Of course wide, stacked and close were a bit novel then, but pretty ubiquitous today, where I believe the vast majority of SoCs actually carry their DRAM burden on their back?[top? It’s so hard to tell with all this flip-chippery going on…] and that doesn’t seem to put them into HPC price ranges, where HBM thrives and gets significant scale.
So what gives? HBM from what I gather is still 10x on price vs DRAM and GDDR something tends to be 2-3x. And GDDR actually seems to require quite a bit of special signal and logic engineering to fine tune timing along much longer and off-die carrier traces. By comparison, HBM seemed almost less of a challenge for transmission logic.
That wide and close (stacked, too?) isn’t an entirely bad idea has been demonstrated by the rotten fruit cult, which seems to use commodity RAM-parts if not packaging.
Naïve as I am, I keep thinking that the major obstacle to HBM commodity pricing has been its niche position and therefore scale, but that should flip naturally given the rather general memory wall pressure.
So where are the real technological/economical barriers to making HBM if not the exclusive RAM on mobile and desktop, then at least a more normal part of any workstation?
Chiplet designs are several generations established even in the consumer space, and with 192GB max capacity on an Apple chip, which would be interesting if it wasn’t tied into their indenture, even my RAM expansion anxiety is receding, perhaps CXL to the rescue in corner cases.
Stacking is extremely normal these days, from flash to just high-density DRAM, so that wouldn’t really explain the price gap. Wide is never cheap, but there is such a variety of materials and packaging technologies addressing this and then where you can put CCDs, you can also put HBM, especially with Infinity Fabric, I believe.
Having to tie down RAM capacity at SoC production is a bother, but even today there is little difference to soldered RAM, which is never near the capacity nor the price that I prefer and believe adequate. So there is a bit of a risk of winding up with inventory that won’t sell at optimal prices.
What am I missing?
TSVs I guess. But as the AMD V-cache chips prove, even TSVs don’t convert commodity parts in unobtainium any more, they have become a manageable part of the technology stack.
Of course, when you need to stack DRAM chips not just in two layers but some nice binary multiple, the risk of something going wrong in the middle killing the entire stack needs to be paid somewhere.
But unless you’re in HPC territory, your HBM stacks don’t need to be that high, TSVs don’t have to run the entire building, just enough floors until the bandwidth is right. And then you can stack these bundles again, using wires at the edge or even lower density interposer chiplets creating risk breakers or intermediate level lobbies, without having to expand in terms of ground floor space.
One of the greatest benefits of the PC space during the last four decades has been its modularity, the ability for an owner to compose what he wanted. The point of composition has now firmly moved to the SoC level, while traditional players still try to claw out ever bigger parts of the cake for their own.
That obviously leaves a lot of potential for creative solutions on the table, you wind up paying excess capacity at every component, because a more synergic solution only works with the kind of scale that clouds and Apple can muster.
Alas the PC started with a processor ASIC and lots of TTL to build everything else. Chipsets ingested TTL chips and then other ASICs and today we see not just single chip PCs, but pretty much rack-on-chip coming and only the big boys still get to play personal computing. Reply
ballsystemlord - Thursday, July 27, 2023 - link
(Holy wall of text, Batman!)> What am I missing?
Well, more pins means more money. There's very little competition, from what I've read, on the packaging front.
I've heard that HBM has one or more patents on it and you have to license them all in order to produce HBM.
If you only have 1 or 2 companies producing HBM then the price will be close to whatever they make it. Sort of like AMD and Nvidia driving up recent GPU pricing.
You also need an interposer as normal PCB routing doesn't work for such high-density interconnects. This means a whole slab of silicon for the chips to sit on.
I think that's everything. Reply
James5mith - Saturday, July 29, 2023 - link
> So what gives? HBM from what I gather is still 10x on price vs DRAM...If demand outstrips supply, the price won't go down, and instead will continue to stay high. Until Datacenter/AI GPU compute doesn't demand every last chip of HBM it can get it's hands on, the chances of price dropping and the tech being implemented in the consumer space is very low. Reply
Calle2003 - Thursday, July 27, 2023 - link
32 Gigabit only? Reply